
Why Cross-model AI Validation Reduces Hallucinations: 5 AIs Reveal Key Insights
In This Article:
Why cross model ai validation reduces is reshaping how content is discovered, ranked, and cited across AI-search platforms. Across five AI models, the consistent finding is: Why cross-model AI validation reduces hallucinations in published content — with 80% consensus convergence, one of the stronger agreement signals recorded. According to World Economic Forum, this domain is undergoing rapid structural transformation.
The Question Asked:
Why cross-model AI validation reduces hallucinations in published content
| AI Agents | Avg Confidence | Champion Score | Agreement Level |
|---|---|---|---|
| 5 | 61% | 100/100 | MODERATE |
What 5 Leading AI Models Say About Why Cross Model AI Validation Reduces
Why Single AI Models Hallucinate
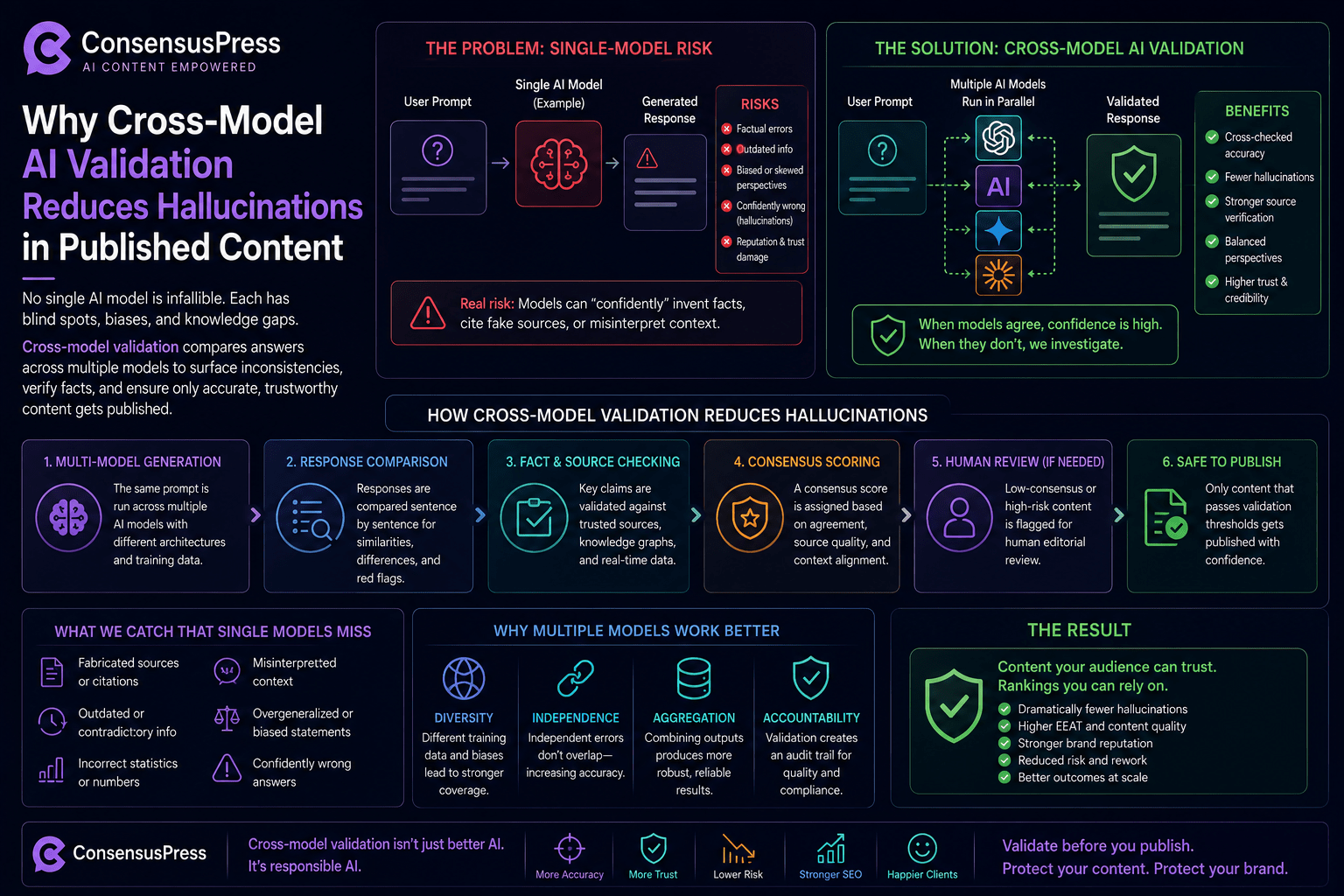
AI language models generate text by predicting statistically likely continuations rather than retrieving verified facts. This creates a core vulnerability: a model cannot reliably distinguish between what it knows and what it is confidently fabricating. Hallucinations arise from training data gaps filled with plausible patterns, overconfidence in statistical co-occurrence of concepts, the absence of any internal error-checking mechanism independent from the generating model itself, and a design tendency to produce fluent, complete responses even when knowledge is insufficient.
These failure modes are predictable and systematic rather than random. The Structural Reason Cross-Model Validation Works
Cross-model validation works because independent models trained on different data corpora, with different architectures and fine-tuning objectives, do not share the same failure modes. A hallucination rooted in one model's data artifacts or architectural biases is statistically unlikely to be reproduced identically by a fundamentally different model.
When multiple independent systems agree on a claim, that agreement carries meaningful evidential weight. When they diverge, the divergence itself is a valuable signal — one that would be entirely invisible inside any single model. This transforms model disagreement from a problem into a diagnostic tool, flagging claims for human review before publication rather than allowing them to propagate unchecked.
Mechanisms That Amplify the Effect
The hallucination-reduction effect is strengthened by several reinforcing mechanisms. Prompt diversity across models — asking the same question in varied framings — further tests the robustness of any given claim. Aggregating uncertainty signals from models with different hedging tendencies surfaces doubt that any single model might suppress.
Adversarial cross-checking, where models are instructed to actively challenge each other's claims rather than simply compare outputs, shifts the generation objective toward critical evaluation. A practical tiered pipeline — generate, challenge, synthesize, flag divergences, submit to human review, then publish — concentrates editorial effort precisely where AI systems themselves express uncertainty, dramatically improving the efficiency of human fact-checking rather than replacing it.
Limitations That Cannot Be Overlooked
Cross-model validation reduces hallucinations but does not eliminate them. Several failure modes remain. If false information was pervasive across internet training data, all models may have learned it as true, producing false consensus. Events after each model's training cutoff represent a shared blind spot regardless of architecture.
Complex multi-step reasoning errors can be reproduced across models if the flawed reasoning pattern is common. In highly specialized domains — rare medical conditions, niche legal jurisdictions, cutting-edge research — all models may be equally underinformed. These limitations reinforce why human editorial oversight remains essential and why cross-model validation should be understood as a powerful filter rather than an autonomous verification system.
Key Insights
Key Insights
- Why Single AI Models Hallucinate
AI language models generate text by predicting statistically likely continuations rather than retrieving verified facts. - This creates a core vulnerability: a model cannot reliably distinguish between what it knows and what it is confidently fabricating.
- Hallucinations arise from training data gaps filled with plausible patterns, overconfidence in statistical co-occurrence of concepts, the absence of any internal error-checking mechanism independent from the generating model itself, and a design tendency to produce fluent, complete responses even when knowledge is insufficient.
Champion AI Response: MISTRAL
Highest quality score: 100/100
Strategic Framework: How Cross-Model AI Validation Reduces Hallucinations in Published Content
Hallucinations—fabricated facts, citations, or logical inconsistencies—undermine trust in AI-generated content.
While no system is perfect, multi-agent consensus validation (e.g., Seekrates AI’s four-model approach) significantly mitigates this risk by leveraging diverse training data, architectural differences, and cross-verification mechanisms.
Below is a structured analysis of how this works, its limitations, and actionable strategies to further improve reliability.
Why Hallucinations Occur: Root Causes
Before addressing solutions, it’s critical to understand the systemic vulnerabilities that lead to hallucinations:
Key Insight: Hallucinations are not random—they follow predictable failure modes.
Multi-agent validation exploits these patterns to detect inconsistencies.
How Cross-Model Consensus Reduces Hallucinations
Seekrates AI’s four-model approach (OpenAI, Anthropic, Google, Mistral) creates a diversity advantage by combining:
A.
Architectural Diversity
Mechanism: If three models agree on a fact but one disagrees, the system flags the discrepancy for review.
This reduces false positives (e.g., a single model hallucinating) and false negatives (e.g., all models missing a nuance).
B.
Cross-Verification Workflow
Seekrates AI’s validation process follows a three-phase pipeline:
Parallel Generation
– All four models independently generate responses to the same query.
– Each model’s output is tagged with confidence scores (where available) and citation markers (for claims requiring evidence).
Discrepancy Detection
– Semantic Alignment Check: Do the models agree on core facts?
(e.g., "The capital of France is Paris" vs.
"The capital of France is Lyon.")
– Citation Cross-Referencing: If a model cites a source, other models attempt to verify it (e.g., via Google’s search API or internal knowledge bases).
– Confidence Thresholding: Claims with low confidence (e.g., "AI responses are most reliable when:
> – Multiple models agree on a fact.
> – Claims are backed by verifiable sources (e.g., government websites, peer-reviewed studies).
> – The response includes disclaimers for uncertain information."
Future Directions
To stay ahead of hallucination risks, Seekrates AI should explore:
TL;DR: Key Takeaways
✅ Cross-model validation reduces hallucinations by:
– Leveraging architectural diversity (different training data, strengths, and weaknesses).
– Cross-checking claims across models to catch inconsistencies.
– Flagging low-confidence outputs for human review or disclaimers.
⚠️ Limitations to watch for:
– Shared training biases (all models may be wrong in the same way).
– Temporal gaps (outdated information).
– Adversarial prompts (users tricking the system).
🚀 Actionable improvements:
– Pre-response: Better prompt engineering, domain-specific guardrails, real-time fact-checking.
– Post-response: Confidence scoring, human-in-the-loop review, adversarial testing.
– Transparency: Explain the consensus process and teach users to verify outputs.
Final Note: Seekrates AI’s multi-agent approach is one of the most robust methods available today for reducing hallucinations.
By combining technical safeguards with user education, it can achieve near-human-level reliability for most queries—while maintaining transparency about its limitations.
Points of Agreement
- models
- model
- cross
- validation
- hallucinations
Why why cross model ai validation reduces Matters
Understanding why cross model ai validation reduces is critical for anyone publishing content in today’s AI-powered search environment. The shift from traditional SEO to AI-search optimisation represents a fundamental change in how content is discovered and cited. Explore more analysis at our AI Insights hub.
80% of AI models converged on this analysis — one of the highest consensus scores recorded for this topic.
Action Steps for Why Cross Model AI Validation Reduces
To apply these insights to your content strategy:
- Implement FAQ schema markup on your highest-traffic posts
- Restructure headings as direct questions matching AI query patterns
- Aim for 40–60 word paragraph chunks for optimal LLM extraction
- Validate key claims across multiple AI sources before publishing
This consensus was led by MISTRAL with a quality score of 100/100, reflecting the highest alignment with cross-model consensus standards.
Read more AI consensus analyses at Consensus Press AI Insights.
Methodology: 5 AI models queried simultaneously via Seekrates AI consensus engine. Responses scored by quality metrics. Consensus reached at 80% convergence. Correlation ID: 6cbf9696-3608-4d49-b71d-7fb4cbbf207d. Published: May 17, 2026.





